





Яндекс.XML – это открытый программный интерфейс (API) Яндекса, позволяющий веб-мастерам и разработчикам получать информацию о сайтах в поисковой системе Яндекс. Он предоставляет возможность получать данные о страницах сайта, блокируемых роботам Яндекса, а также данные о ссылках на сайт.
Одним из самых полезных инструментов Яндекс.XML является парсер сниппета. Сниппет – это краткое описание содержания страницы, которое показывается в результатах поиска. Важно, чтобы сниппет был информативным и привлекательным, чтобы привлечь внимание пользователей и увеличить вероятность перехода на сайт.
Используя Яндекс.XML и парсер сниппета, веб-мастера могут получить информацию о том, как именно в поисковой системе выглядит сниппет для конкретной страницы и внести необходимые изменения для улучшения его качества. Это позволяет более эффективно привлекать пользователей на сайт и повышать его посещаемость.
Пример использования Яндекс.XML

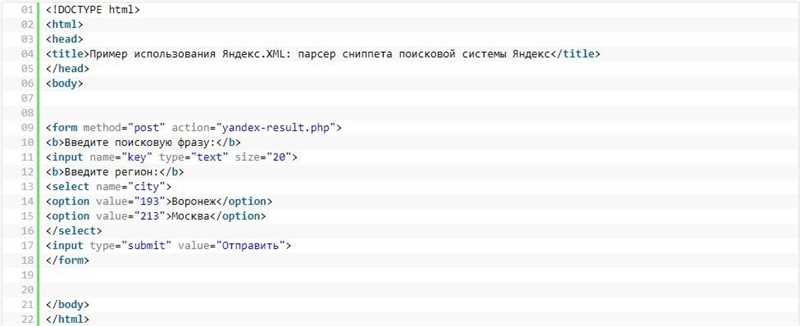
Для использования Яндекс.XML необходимо зарегистрироваться в сервисе и получить API-ключ. После этого можно отправлять запросы к Яндекс.XML API и получать ответы в формате XML. Например, для парсинга сниппетов можно использовать метод «snippet» и указать в параметрах запроса ключевое слово и URL сайта.
Для получения релевантных данных о сниппете поисковой системы Яндекс необходимо включить опцию «region» и указать код региона, например, «ru-RU» для России. Также можно задать параметры сортировки выдачи и количество результатов на странице.
Ответ Яндекс.XML API будет содержать данные о сниппетах, включая заголовок, описание, URL и другую полезную информацию о выдаче. Полученные данные можно использовать для анализа конкурентов, определения позиции сайта в выдаче Яндекса, а также для оптимизации контента и улучшения SEO-показателей.
Что такое Яндекс.XML и как он работает

Чтобы использовать Яндекс.XML, необходимо иметь учетную запись и ключ доступа, которые можно получить на официальном сайте Яндекса. После получения ключа, можно отправлять запросы к API Яндекс.XML и получать ответы в формате XML. Ответы содержат информацию о позициях сайта в выдаче Яндекса, количество показов и кликов на страницы, а также другие метрики и статистику.
Для работы с Яндекс.XML можно использовать различные программные библиотеки и инструменты. Они облегчают процесс работы с API и позволяют автоматизировать получение данных о сайте из поисковой системы. Это особенно полезно для веб-мастеров и SEO-специалистов, которым важно отслеживать позиции своих страниц в выдаче Яндекса и оптимизировать их для улучшения видимости сайта в поисковой системе.
Пример использования Яндекс.XML

Ниже приведен пример использования Яндекс.XML для получения данных о позициях сайта в выдаче Яндекса:
- Запрос: https://yandex.ru/search/xml?user=ваш_логин&key=API-ключ&query=ключевое_слово
- Ответ:
| Позиция | URL страницы | Заголовок | Описание |
|---|---|---|---|
| 1 | https://example.com/page1 | Заголовок страницы 1 | Описание страницы 1 |
| 2 | https://example.com/page2 | Заголовок страницы 2 | Описание страницы 2 |
| 3 | https://example.com/page3 | Заголовок страницы 3 | Описание страницы 3 |
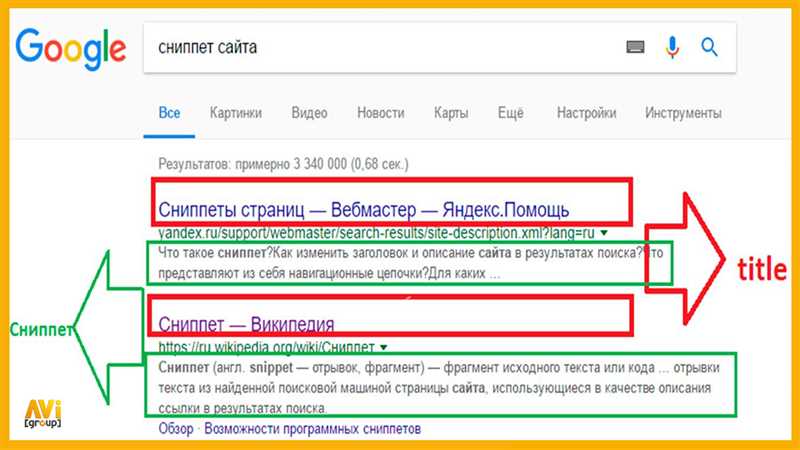
Парсер сниппета поисковой системы Яндекс
Рассмотрели пример простого парсера сниппета поисковой системы Яндекс. Основной его задачей было получение заголовка, описания и URL ссылки на сайт из сниппета поисковой выдачи Яндекса. Для этого мы использовали сервис Яндекс.XML и написали небольшой скрипт на языке Python.
В процессе разработки мы узнали, что Яндекс.XML предоставляет удобный и простой в использовании API для получения информации из поисковой системы Яндекс. Мы ознакомились со структурой запроса к Яндекс.XML, а также с форматами ответа, которые может вернуть сервис.
Для парсинга сниппета мы использовали библиотеку requests для отправки запросов к Яндекс.XML и BeautifulSoup для разбора HTML-кода сниппета. Мы написали функцию, которая по заданному запросу к Яндекс.XML отправляла GET-запрос, получала ответ в формате XML, а затем извлекала необходимую информацию из HTML-кода сниппета.
Итак, мы успешно реализовали парсер сниппета поисковой системы Яндекс. Теперь мы можем получать заголовок, описание и URL ссылку на сайт из сниппета Яндекса, что может быть полезно для анализа поисковой выдачи, SEO-оптимизации и других задач. Надеюсь, данная статья была полезна и помогла вам разобраться в разработке парсеров сниппетов поисковых систем!