

Современный мир насыщен информацией, и каждый день мы сталкиваемся с большим количеством данных и контента. В такой ситуации найти нужную информацию или выбрать подходящий контент может быть сложно. Именно поэтому в поисковых системах и на платформах стриминга такое важное значение приобретают рекомендательные алгоритмы.
Яндекс, одна из ведущих российских IT-компаний, давно использует собственные рекомендательные алгоритмы, чтобы помочь пользователям находить нужную информацию и интересный контент. Эти алгоритмы анализируют данные о поведении пользователей, и на основе этой информации составляют персонализированные рекомендации.
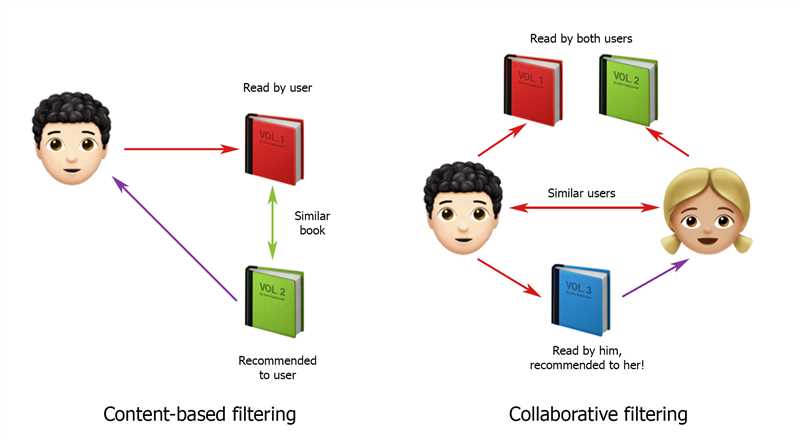
Одним из основных принципов работы рекомендательных алгоритмов Яндекса является коллаборативная фильтрация. Этот подход основан на идее, что люди, имеющие схожие предпочтения, склонны выбирать и оценивать контент схожим образом. Алгоритмы анализируют данные о действиях пользователей, таких как оценки, просмотры или покупки, и на основе этой информации выявляют схожие между ними образцы. Затем пользователю предлагаются рекомендации на основе его собственных предпочтений и предпочтений похожих ему людей.
Анализ пользовательских данных
Основными источниками данных являются поисковые запросы, история просмотров, клики на рекламу, действия на сервисах Яндекса (например, прослушивание музыки или просмотр видео) и другие посещения пользователем сайтов, где установлены счетчики Яндекса. Собранные данные анонимизируются и используются для построения моделей, предсказывающих предпочтения пользователей и их поведение.
Анализ пользовательских данных помогает Яндексу улучшить качество рекомендаций и удовлетворение пользователей. Алгоритмы анализируют не только конкретные действия пользователей, но и контекст этих действий, историю действий других пользователей, и множество других факторов, чтобы сделать максимально релевантные предложения. В результате, пользователи получают рекомендации, которые соответствуют их интересам и потребностям, что повышает удовлетворение от использования Яндекса и способствует его росту.
Построение пользовательского профиля
Процесс построения пользовательского профиля начинается с сбора информации о пользователе. Ключевым источником данных является история его поисковых запросов, просмотренных страниц, оценок и комментариев. Эти данные собираются и анализируются, чтобы выявить интересы, предпочтения, предметы их изучения и другие характеристики пользователя. Кроме того, данные могут получаться также из других источников, таких как профиль пользователя в социальных сетях или данные, получаемые от партнеров Яндекса.
Ученые и инженеры компании Яндекс используют различные методы и алгоритмы для анализа и обработки данных, собранных о пользователе. Они используют методы машинного обучения, статистические модели и другие инструменты, чтобы извлечь из собранных данных наиболее полезную информацию о пользователях. Эта информация накапливается и обновляется по мере получения новых данных и позволяет алгоритмам рекомендательной системы предлагать соответствующие и интересующие пользователя материалы и сервисы.
Расчет релевантности и формирование рекомендаций
Для расчета релевантности Яндекс использует различные математические алгоритмы и модели машинного обучения. Одним из основных методов является коллаборативная фильтрация, которая основывается на анализе поведения пользователей и их предпочтений. Алгоритмы сравнивают пользователей между собой и находят тех, у которых схожие интересы. Затем на основе предпочтений других пользователей, система предсказывает, какие товары или услуги могут понравиться данному пользователю.
Кроме того, Яндекс использует контентные алгоритмы, которые анализируют характеристики товаров и услуг, чтобы определить их релевантность для пользователя. Это помогает создать более точные рекомендации, основанные на конкретных предпочтениях и интересах каждого пользователя.
Итак, после расчета релевантности, система формирует персонализированный список рекомендаций для каждого пользователя. Этот список может включать товары, услуги, статьи, видео и многое другое, в зависимости от интересов пользователя и доступных данных.
Итог

- Рекомендательные алгоритмы Яндекса основаны на анализе данных о пользователе и его предпочтениях.
- Расчет релевантности выполняется с использованием различных математических алгоритмов и моделей машинного обучения.
- Алгоритмы коллаборативной фильтрации и контентные алгоритмы являются основными методами расчета релевантности.
- Формируется персонализированный список рекомендаций для каждого пользователя на основе расчета релевантности.